I am going to be taking results of peoples Sex, eye colour, hair colour, fixed or free ear lobe and whether they have the ability to roll their tongue.
I feel that if I take a range of continuous variation results I will not be able to make a good conclusion because the test will not be fair. I hope to see the variants to eventually balance out on a graph, however this may not happen because not enough results have been able to be taken.
I predict that the results will equal out to a 50:50 ratio, if they do not then a wider range of results would need to be taken. A collection of results for the whole of Bristol would show a better balance of features than a collection of results for 40 people.
There isn’t anything dangerous that can happen.
The equipment that I will be using is very basic, I will just be writing down, in a table different characteristics about people.
To do my experiment I will be going around the class, and various other places for a wider range of results, taking information about each person, and putting it into a table, eventually the results will go into a graph for analysis.
Factors that may affect my experiment could include “red herrings”, for example, if a detached earlobe isn’t so obviously detached, an attached earlobe which is fairly fat, or if some people dye their hair but claim that it’s a natural colour. There are also people whose hair is affected by the season, e.g. some people who have brown hair, in the summer turns blonde because of the increase in sun shining on it. I ceased to choose continuous variation because these results can be affected by the diet that someone has, which could corrupt a weight category or even height.
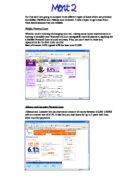
Here are my results:
From my results I can see that in some cases the variants seem to balance out but in others it is not so straightforward.
From this I can conclude that the results balance out to a certain degree, as explained by the equal distribution rule in nature. There is a graph called to equal distribution graph that shows that everything is equalled out.
THE NORMAL DISTRIBUTION CURVE
On the gender graph I can see that from the thirty-eight people I analysed there were 20 (53%) males and 18 (47%) this is very close to 50:50, which supports my prediction, the earlobe graph also supports my prediction to and extent and also the eye colour graph supports by prediction.
The hair colour graph, however does not support my prediction there is 79% and 21%, neither does the Tongue roller graph with 26% non rollers which is a big difference to just dismiss.
My experiment worked fairly well. I collected many results; I made a conclusion and produced graphs.
Most of my results seemed accurate enough because most of the graphs showed as I had expected.
There was really no other way to do this experiment, other than going to people and collecting information about them, unless a database was kept, which contained information about different people.
A way that I could have improved my experiment is to take information about a wider range of people, this would give me a more accurate ground to base my conclusion on, and to see if the hair colour and tongue roller graphs balance out.
My results were very reliable; there wasn’t really any error that could happen.
The unexpected graph were those of the Hair colour and Tongue roller. The two main colours didn’t balance out in any way, neither did the tongue rollers and non-tongue rollers. The only way that I can explain this is that not enough results were taken to come to a firm conclusion on the hair colour and tongue rolling, but the other three fields support my prediction so I am very confident that the hair colour and tongue roller distribution would equalise eventually.
Apart from the hair colour, and tongue rolling I had enough results to come to a conclusion confidently.
If I had more time I would have gone into continuous variation, and worked out averages for heights, weights, hand spans, etc.